
Deepfakes stellen eine große Bedrohung für die Demokratie dar, gefährden aber auch Privatpersonen und Unternehmen. Beispielsweise wird Industriespionage möglich gemacht, indem Angreifer in Video- oder Telefongesprächen ihre Identität via Deepfakes verfälschen und somit vertrauliche Informationen erlangt. Ähnlich kann durch Trickbetrug Geld ins Ausland überwiesen werden. Wie kann man sich dagegen schützen? Es gibt drei zentrale Ansätze:
- Aufklärung und Schulung: Die Bevölkerung muss darüber aufgeklärt werden, dass sowohl Video- als auch Audio-Deepfakes existieren und wie sie missbraucht werden. Darüber hinaus ist beispielsweise im Audio-Bereich die Schulung des Gehörs möglich, um gefälschte Audiospuren zu identifizieren (siehe Deepfake-Erkennung: Spot the Deepfake).
- Verifizierung und Signatur von Medieninhalten: Technologien, wie die Content Authenticity Initiative, ermöglichen es, die Echtheit von Medieninhalten zu überprüfen (siehe Content Authenticity Initiative).
- KI-gestützte Deepfake-Erkennung: Hierbei werden KI-Systeme entwickelt, die in der Lage sind, unbekannte Audioaufnahme zu analysieren und festzustellen, ob sie echt oder gefälscht ist. Diese KI-Detektoren sind hierbei bestrebt, auch die neusten Deepfakes zuverlässig zu identifizieren, während die Deepfake-Ersteller alles tun, um nicht erkannt zu werden. Ähnlich wie in der Antivirus-Erkennung ist das ein stetiger Wettbewerb, in dem es für den Verteidiger darum geht, die Hürde für den Angreifer derart hoch zu machen, dass sich ein Angriff nicht mehr lohnt.
Ein Beispiel für den Einsatz eines KI-gestützten Erkennungssystems ist die folgende Analyse eines Audio-Deepfakes. In dieser gefälschten Aufnahme wird dem britischen Premierminister Keir Starmer folgende Aussage unterstellt: »Ich kümmere mich nicht wirklich um meine Wählerschaft und hintergehe sie.« Bei der Deepfake-Erkennung auf der Plattform Deepfake-Total, wird die Aufnahme als Fälschung erkannt, wie im folgenden Screenshot zu sehen: Die Anzeige des Deepfake-O-Meters ist rot.
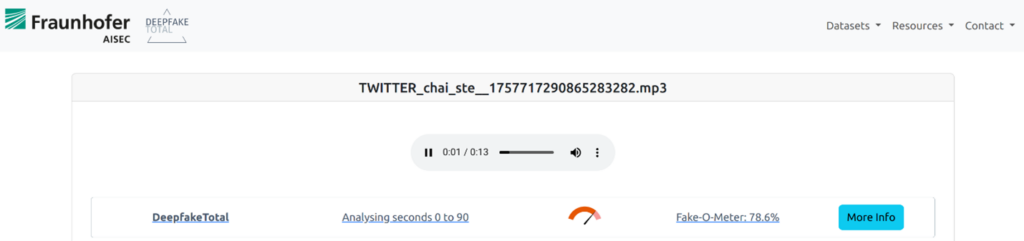
Abbildung 1: Analyse des Keir Starmer Audio-Deepfakes durch http://deepfake-total.com/
Der MLAAD Datensatz
Die Grundlage jeder KI-gestützten Deepfake-Erkennung bildet der zugrundeliegende Datensatz. Hier werden geeignete Beispiele originaler und gefälschter Audiospuren gesammelt, um sie anschließend zum Training des Erkennungsmodells verwenden zu können.
Das oben gezeigte Deepfake-Erkennungssystem wurde unter anderem auf dem MLAAD-Datensatz (»Multi-Language Audio Antispoofing Dataset«) trainiert, welches zur hohen Erkennungsrate auch bei neuen und unbekannten Audio-Deepfakes beigetragen hat. Der MLAAD-Datensatz adressiert dabei einige der größten Herausforderungen der Audio-Deepfake-Erkennung:
- Ausgewogenheit der TTS-Systeme: Audio-Deepfakes werden häufig mit Text-to-Speech-Systemen (TTS) erstellt, die in der Lage sind, einen beliebigen Text in der Stimme einer Zielperson zu synthetisieren, wie etwa im Fall von Keir Starmer. Es gibt viele verschiedene TTS-Systeme, die jeweils eigene Charakteristika aufweisen. Einige sind besonders gut darin, emotionale Sprache zu erzeugen, während andere eine nahezu perfekte stimmliche Ähnlichkeit zur Zielperson herstellen können. Trainiert man Erkennungssysteme jedoch nur mit Audiodaten von wenigen TTS-Systemen, können sie nur die spezifischen Merkmale dieser Systeme erkennen.
Die Deepfake-Erkennung ist daher datenhungrig: Je größer die Vielfalt der im Trainingsdatensatz enthaltenen Deepfake-Daten ist, desto besser funktioniert die Erkennung. Der MLAAD-Datensatz umfasst derzeit bereits 59 verschiedene TTS-Systeme – mehr als jeder andere Datensatz – und wird kontinuierlich erweitert, um die Vielfalt weiter zu erhöhen.
- Ausgewogenheit der Sprachen: Ähnlich wie bei den TTS-Systemen ist auch eine Vielfalt an Sprachen wichtig. Herkömmliche Datensätze enthalten oft nur englische oder chinesische Audiospuren. Deepfakes werden aber in vielen verschiedenen Sprachen erzeugt. Ein Erkennungssystem, das nur auf Englisch trainiert ist, wird Deepfakes in anderen Sprachen nicht zuverlässig erkennen. Der MLAAD-Datensatz enthält über 35 verschiedene Sprachen – das sind ebenfalls mehr als in jedem anderen Datensatz.
Zur Erzeugung dieses MLAAD-Datensatzes haben wir, wie oben bereits angedeutet, 59 verschiedene TTS-Systeme verwendet. Es wurden teilweise eigens konzipierte Systeme verwendet, beziehungsweise neuartige Ansätze aus Open-Source-Sammlungen zusammengetragen. Diese haben wir nach einem einheitlichen Schema angewandt, was in der folgenden Abbildung visuell dargestellt ist:
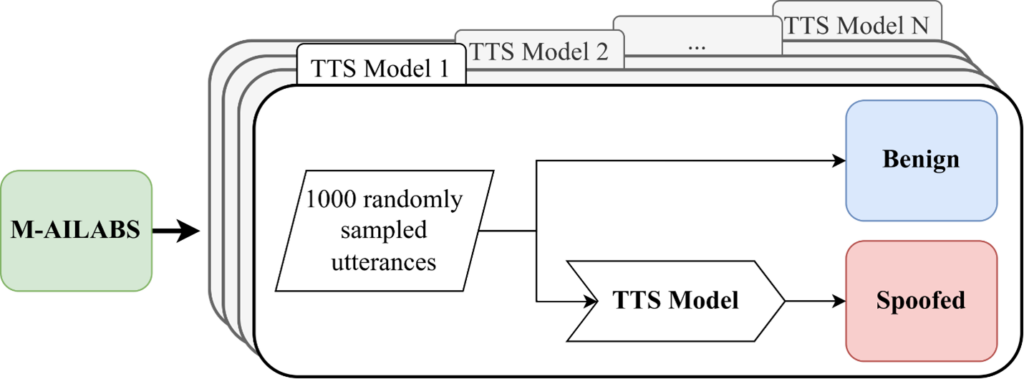
Abbildung 2: Erstellung des MLAAD Datensatzes.
Wir verwenden als Ausgangsbasis den M-AILABS-Datensatz, der Audiospuren in acht Sprachen umfasst: Englisch, Französisch, Spanisch, Italienisch, Polnisch, Deutsch, Russisch und Ukrainisch. Um die Vielfalt zu erhöhen, übersetzen wir – falls erforderlich – den Text dieser Aufnahmen automatisiert in eine von insgesamt 35 Sprachen. Anschließend synthetisieren wir mit jedem der 59 TTS-Modelle 1000 Audiospuren. Dies führt zu einer bisher nicht gekannten Vielfalt an Deepfake-Sprachdaten.
Der MLAAD-Datensatz als Basis für Forschungsfragen
Neben dem praktischen Nutzen unseres Datensatzes ist auch der Nutzen für die wissenschaftliche Forschungsgemeinschaft enorm. Diese kann nun kontrolliert überprüfen, welche Charakteristika in Audio-Deepfakes wie gut erkannt werden können. Beispielsweise kann man überprüfen, ob deutsche Deepfakes besser oder schlechter erkannt werden können als englische oder spanische. Darüber hinaus hilft ein Datensatz mit 59 Deepfake-Modellen auch bei weiteren Disziplinen wie dem »Source Tracing«. Dabei geht es um die Beantwortung der Frage, welches KI-System ein gegebenes Deepfake erstellt hat. MLAAD wurde beispielsweise bereits von Forschern aus den USA genutzt: https://arxiv.org/abs/2407.08016.
Wrap-Up
Die Zuverlässigkeit von KI-Erkennungsmodellen ist sehr stark abhängig von der Qualität der Trainingsdaten. Ein hochwertiger Datensatz zur Erkennung von Deepfakes zeichnet sich durch Vielfalt und Ausgewogenheit aus. Der MLAAD-Datensatz enthält Audiodaten aus 35 Sprachen und nutzt 59 verschiedene Text-to-Speech-Systeme, um eine große Bandbreite an Merkmalen abzudecken. Er unterstützt u.a. bei der Entwicklung robuster Antispoofing-Methoden und der Analyse der Herkunft von Deepfakes.
Datensätze wie MLAAD sind ein wichtiger Baustein für die KI-gestützte Erkennung von Deepfakes und damit für den Kampf gegen Desinformation, die Sicherung der Demokratie und den Schutz von Privatpersonen sowie Unternehmen.
Weiterführende Informationen
Autor

Nicolas Müller
Dr. Nicolas Müller promovierte 2022 an der Technischen Universität München im Fachbereich Informatik mit der Dissertation über »Integrität und Korrektheit von KI-Datensätzen«. Davor absolvierte er ein Studium in Mathematik, Informatik und Theologie an der Universität Freiburg, das er 2017 mit Auszeichnung abschloss. Seit 2017 ist er als Machine Learning Scientist am Fraunhofer-Institut für Angewandte und Integrierte Sicherheit AISEC in der Abteilung Cognitive Security Technologies tätig. Sein Forschungsschwerpunkt liegt auf der Zuverlässigkeit von KI-Modellen, der Identifizierung von Machine-Learning-Shortcuts und der KI-gestützten Erkennung von Audio-Deepfakes.
Kontakt: nicolas.mueller@aisec.fraunhofer.de





