
Deepfakes are a major threat to democracy, but also to private individuals and companies. One example is attackers using deepfakes to create a false identity in video or phone conversations to obtain confidential information for industrial espionage. Or they may use it to make fraudulent money transfers abroad. But what can we do to prevent this? There are three main approaches:
- Education and training: The public needs to be educated that both video and audio deepfakes exist and how they are being exploited. Additional measures include training the ear to identify fake audio tracks (see Deepfake Detection: Spot the Deepfake).
- Verification and signature of media contents: Technologies such as the Content Authenticity Initiative enable verification of media authenticity (see Content Authenticity Initiative).
- AI-assisted deepfake detection: This involves developing AI systems that can analyze unknown audio recordings and determine whether they are real or fake. These AI detectors are designed to reliably identify even the latest deepfakes, while deepfake creators are doing everything they can to avoid being detected. Similar to antivirus detection, this is an ongoing competition in which the defender’s goal is to raise the bar for the attacker so high that an attack is no longer worthwhile.
An example for the use of an Ai-assisted detection system is the following analysis of an audio deepfake. In this fake recording, British Prime Minister Keir Starmer is said to have made the following statement: »I don’t really care about my constituents and I’m deceiving them.« When deepfake recognition is applied to the platform Deepfake Total, the recording is recognized as a fake, as can be seen in the following screenshot: The Deepfake-O-Meter is red.
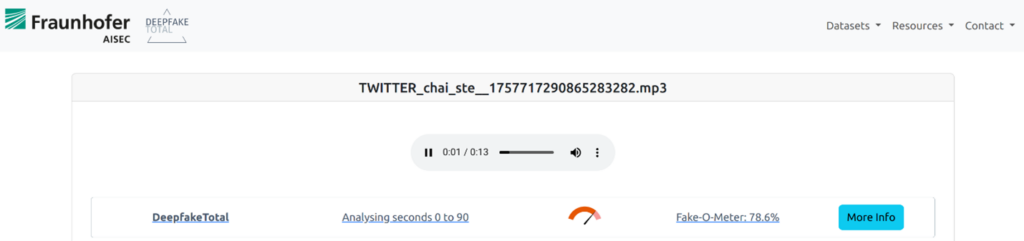
Figure 1: Analysis of the Keir Starmer audio deepfake through http://deepfake-total.com/
The MLAAD dataset
The basis of any AI-assisted deepfake detection is the underlying dataset. Suitable samples of original and fake audio tracks are collected, which are then used to train the detection model.
The deepfake detection system shown above was trained on the Multi-Language Audio Anti-Spoofing Dataset (MLAAD), which contributed to the high detection rate even for new and unknown audio deepfakes. The MLAAD dataset addresses one of the major challenges of audio deepfake detection:
- Balanced TTS systems: Audio deepfakes are often created using text-to-speech (TTS) systems that can synthesize any text in the voice of the target person, as was the case with Keir Starmer. There is a large variety of TTS systems, each with its own characteristics. Some are particularly good at creating emotional speech, while others can create a near-perfect vocal resemblance to the target person. However, training detection systems on audio data from only a few TTS systems means they will only be able to detect the specific features of those systems.
Deepfake detection requireslarge amounts of data: The more diverse the deepfake data in the training set, the better the detection. The MLAAD dataset currently includes 59 different TTS systems — more than any other dataset — and is continuously being expanded to further increase diversity.
- Balanced languages: Similar to TTS systems, it is also important to include a large variety of languages. Frequently, conventional datasets only include English or Chinese audio tracks, even though deepfakes are created in many different languages. Deepfakes in other languages cannot be reliably detected by a detection system trained only in English, for example. MLAAD includes 35 different languages, again more than any other dataset.
As indicated above, we used 59 different TTS systems to create this MLAAD dataset. In some cases, specially designed systems were used, or new approaches were developed from open-source collections. We applied them according to a standardized model, which is illustrated in the following figure:
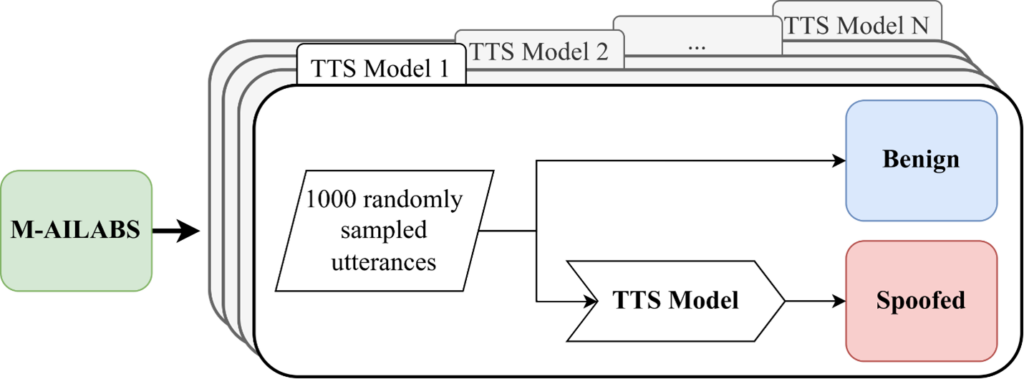
Figure 2: Creating the MLAAD dataset.
As a starting point, we use the M-AILABS dataset, which contains audio tracks in eight languages: English, French, Spanish, Italian, Polish, German, Russian and Ukrainian. To increase variety, we automatically translate the text of these recordings into one of a total of 35 languages, if necessary. We then synthesize 1,000 audio tracks with each of the 59 TTS models, creating an unprecedented diversity of deepfake speech data.
The MLAAD dataset as a base for research questions
Apart from the practical benefits that our dataset offers, there are also great benefits for the scientific community. Researchers can now check in a controlled manner which characteristics in audio deepfakes can be detected and with what accuracy. For example, it is possible to check whether the detection of German deepfakes is better or worse than for English or Spanish deepfakes. A dataset with 59 deepfake models also helps in other disciplines such as source tracing. Its purpose is to determine which AI system created a given deepfake. MLAAD has already been used by researchers in the USA, for example: https://arxiv.org/abs/2407.08016.
Wrap-Up
The reliability of AI detection models depends largely on the quality of the training data. Diversity and balance are the hallmarks of a high-quality dataset for the detection of deepfakes. The MLAAD dataset contains audio dataset from 35 languages and uses 59 different text-to-speech systems to cover a wide range of characteristics. It assists in developing robust anti-spoofing methods, analyzing the origin of deepfakes, and other challenges.
Datasets such as MLAAD are a critical building block for AI-assisted deepfake detection to combat disinformation, safeguard democracy, and protect individuals and companies.
Further information
Author

Nicolas Müller
Dr. Nicolas Müller received his doctorate in computer science from the Technical University of Munich in 2022 with a dissertation on the »Integrity and Correctness of AI Datasets.« Prior to that, he completed a degree in mathematics, computer science and theology at the University of Freiburg, graduating with distinction in 2017. Since 2017, he has been a machine learning scientist in the Cognitive Security Technologies department at the Fraunhofer Institute for Applied and Integrated Security AISEC. His research focuses on the reliability of AI models, the identification of machine learning shortcuts, and AI-assisted audio deepfake detection.
Contact: nicolas.mueller@aisec.fraunhofer.de






