
Can voice recordings be used to accurately detect a Covid-19 infection? [1]. Is there a reliable way to identify deepfakes? With AI, all this is possible. Various competitions offer datasets that can be used to train machine learning models for these specific applications, resulting in a plethora of scientific publications on the subject [2]. For instance, ever higher success rates in detecting deepfakes are a hopeful sign that it will soon be possible to identify them securely and reliably, allowing them to be removed from social media. Artificial intelligence, it seems, can solve problems that were previously thought unsolvable, often outperforming humans — in chess, the popular board game Go or complex video games like StarCraft II [4], for example.
But caution is advised: While AI is demonstrably successful in some areas, little progress can be discerned elsewhere. According to an MIT article, for example, not one of the more than 100 tools developed to help diagnose Covid-19 was reliable enough to be used in a clinical setting [5]. What is more, some scientists fear that certain tools were even potentially harmful to patients.
These observations are consistent with other studies and experiences from scientific practice [6] [7]. AI models sometimes perform significantly worse in reality compared to expectations from lab tests. But why is that? Is AI just another example of overhyped technology that we will abandon in a few years’ time, once disenchantment sets in?
Why AI works and why it fails
In order to understand why AI sometimes delivers excellent results (in chess, Go and StarCraft) and sometimes fails entirely (in diagnosing Covid), we need to know how it works. AI is actually better described as pattern recognition: Unlike humans, the models do not develop an understanding of semantics; instead, they just learn patterns based on examples in a dataset. Take the problem of distinguishing between horses and camels, for example. Using many example images, AI will learn that these animals differ in terms of their coloring, size and shape. But it will also learn that a paddock in the background of the image correlates almost exclusively with the presence of horses. And that’s where AI comes unstuck: If a camel strays into a paddock in the real world, the AI is confused because it has never seen a camel in a paddock before. Herein lies the difference from humans. Even if we have never seen a situation like a camel in a paddock before, we can imagine it — unlike the AI.
This example illustrates a fundamental problem with AI recognition algorithms: We do not know (exactly) what these models are learning. All we can say for sure is that the data includes every correlation, even those which do not actually help us to understand the problem at all. Have most of the horse pictures been taken in the evening — perhaps with a different camera than the camel pictures? Was there maybe a small speck of dust on the lens when the horse pictures were taken? The model will learn that “speck of dust” and “evening light” are synonymous with “horse” and will otherwise interpret “camel”. This then works accurately on the existing dataset and convinces the scientists that their model works. But of course, it only really works in the lab, under these exact circumstances and with these exact shortcuts. The scientific community is becoming increasingly aware of this problem and has now coined the term “shortcut learning” — that is, learning from erroneously allocated classifiers [8].
This phenomenon may also explain the failure of AI models to detect Covid-19. One example can be found in X-rays of people with and without a confirmed coronavirus infection, most of which come from a range of different hospitals. The model does not learn to distinguish “Covid” from “not Covid”, but rather the pictures of hospital A from hospital B. A similar situation applies, for example, to tubes or other medical equipment, which are seen much more frequently in images of sick people than in those of healthy people [9].
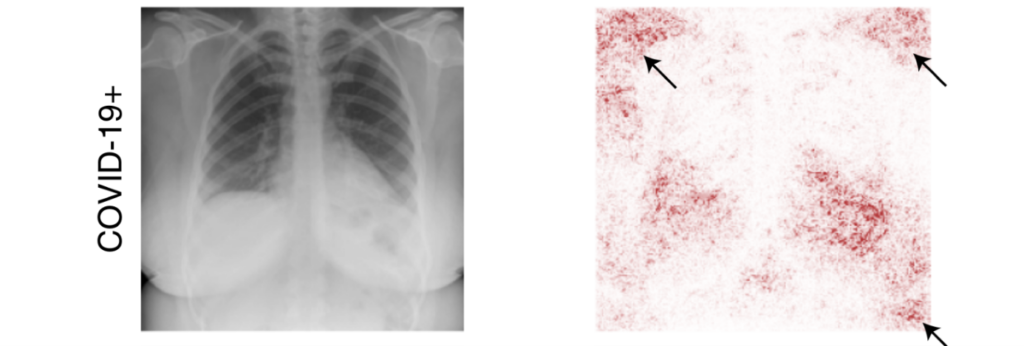
Chest X-ray of patient who has tested positive for Covid-19 (left). Regions contributing to the classification of an AI model (right, in red). It can be seen that the AI is focusing much of its attention on regions outside of the lungs: Thus, the classification of the patient as positive for Covid-19 is also based on shortcuts, such as the position of the shoulder (arrow at top left). Image taken from [9].
Overfitting: One dataset as a measure of all things
However, it is not just shortcuts in the data which can lead us to overestimate the capabilities of individual models. In smaller fields of research such as audio deepfake recognition, the monopoly of one dataset may lead the scientific community to tailor their models too closely to that dataset [10]. This means that all the components of the AI model are optimized to obtain the best possible results in relation to the reference benchmark. The result is that the models operate up to ten times better in theory than in practice [10]. We have to conclude that problems deemed to be solved (such as audio deepfake recognition) actually need to be critically reassessed.
The systematic difference
Some may argue that there are AI models that demonstrably outperform humans — in chess or the board game Go, for instance. So why does AI work in these cases but not in others? One part of the puzzle may be that chess and Go are mastered through what is known as reinforcement learning. The AI is trained using a simulator (such as a chess simulator), in which it plays chess against itself for up to 1,000 years and learns in the process. Unlike the camel/horse image recognition example, there is no fixed dataset in this case; rather, an interactive world in which the model can act, is allowed to make mistakes and is able to learn from them. This AI method, inspired by human learning, appears to be able to produce significantly more robust models than methods based purely on datasets. It could be concluded that AI models should be taught in this way — but in many cases, including problems such as detecting animals or Covid-19, there simply isn’t a simulator available. For that, we would need to model every aspect of the entire world on a computer, which of course is impossible. And so, at least for the moment, AI must make do with fixed datasets in many areas. This leaves researchers faced with the challenge of finding a way to circumvent the problem of shortcuts and benchmark overfitting.
The right way to use ML shortcuts
What can currently be done to solve a data-driven classification problem? As is so often the case, there is no quick fix, but a series of best practices:
- First, if you are collecting data yourself, scrutinize the process and make sure that the target class or classification objective does not correlate with obvious attributes (such as data source, camera type and so on). For example, if a large corpus of data is being labeled, each person working on it (i.e., labeling the dataset) should process examples from all classes, not just one.
- The data situation can also be improved by collecting data from sources that are as wide-ranging as possible, assuming each source contributes roughly the same number of data points to each class (otherwise, the result will be a shortcut like the one from the example above, where the hospital correlates with the prevalence of Covid-19). If a source does contain shortcuts, then a dataset of this kind will at least not be completely flawed.
- An absolute must is the use of Explainable AI techniques (XAI). These are methods from the field of machine learning that show what the model learns (see Fig. 1 above, on the right). This allows us to determine whether the AI model is learning semantically correct features or shortcuts.
- Ultimately, we can resort to automated techniques to remove shortcuts. This works, for example, by defining the maximum percentage of predictive power a pixel may have, and then using loss functions to appropriately edit pixel areas that are deemed too strong or alter ones that are semantically dominant. However, these methods are still in their infancy.
The AI developer (still) needs to be well-versed in the topic of AI shortcuts and able to critically check the model for learning success, especially using XAI methods. In particular, this means setting aside blind faith in benchmarks and test set performance, and realizing that machine learning models perform pattern recognition and learn any kind of correlation, regardless of whether it is wanted. A human then needs to assess whether what has been learned is of value or not.
Author

Nicolas Müller
Nicolas Müller studied mathematics and computer science to state examination level at the University of Freiburg, graduating with distinction in 2017. Since 2017, he has been a research scientist in the Cognitive Security Technologies department of Fraunhofer AISEC. His research focuses on the reliability of AI models, ML shortcuts and audio deepfakes.






